AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
- NeurIPS 2025 -
Recent advancements in Vision-Language-Action (VLA) models have shown promise for end-to-end autonomous driving by leveraging world knowledge and reasoning capabilities. However, current VLA models often struggle with physically infeasible action outputs, complex model structures, and unnecessarily long reasoning.
In this paper, we propose AutoVLA, a novel VLA framework that unifies reasoning and action generation within a single autoregressive generation model. AutoVLA performs semantic reasoning and trajectory planning directly from raw visual inputs and language instructions. We tokenize continuous trajectories into discrete, feasible actions, enabling direct integration into the language model. For training, we employ supervised fine-tuning to equip the model with dual thinking modes: fast thinking (trajectory-only) and slow thinking (enhanced with chain-of-thought reasoning). To further enhance planning performance and efficiency, we introduce a reinforcement fine-tuning method based on Group Relative Policy Optimization (GRPO), reducing unnecessary reasoning in straightforward scenarios.
Extensive experiments across real-world and simulated datasets and benchmarks, including nuPlan, nuScenes, Waymo, and CARLA, demonstrate the competitive performance of AutoVLA in both open-loop and closed-loop settings. Qualitative results further showcase the adaptive reasoning and accurate planning capabilities of AutoVLA in diverse scenarios. We will release the code, model weights, and datasets to facilitate future research in the field.
⚙️ Two Main Components:
🪜 Two Training Stages:
In this experiment, AutoVLA is trained on a mixture of the nuPlan and nuScenes datasets with varying training set sizes (10k, 50k, 100k, 185k).
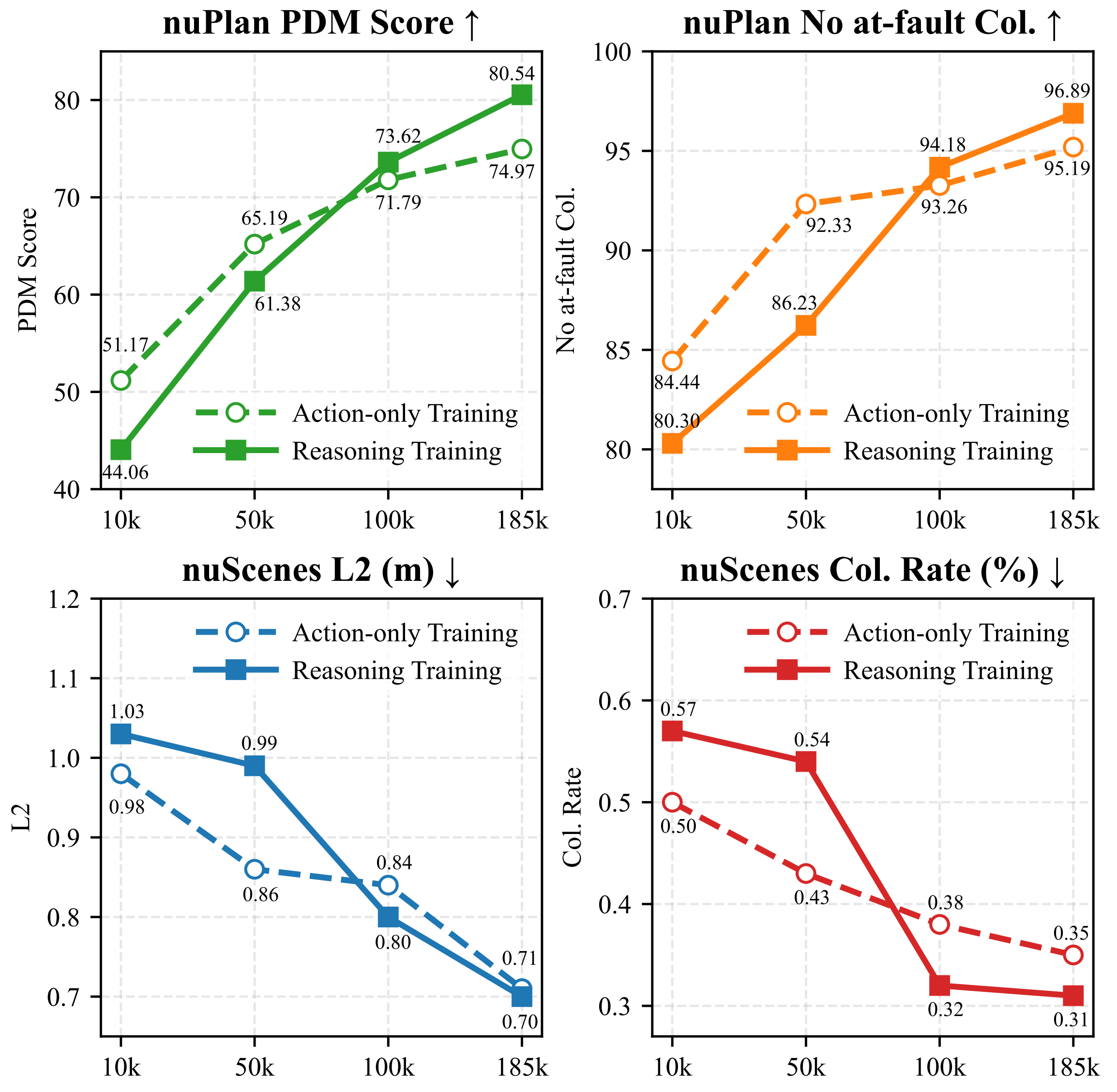

We apply RFT to the full-data CoT reasoning model trained via SFT.

In the Waymo Vision-based End-to-End Driving Challenge (as of May 22, 2025), AutoVLA ranks highly in both RFS Overall and ADE metrics and achieves the top score in the RFS Spotlight metric, which focuses on the most challenging scenarios.

Red lines represent the planning trajectories, and Green lines represent the ground-truth trajectories.
@article{zhou2025autovla,
author = {Zhou, Zewei and Cai, Tianhui and Zhao, Seth Z.and Zhang, Yun and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi},
title = {AutoVLA: A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning},
journal = {arXiv preprint arXiv:2506.13757},
year = {2025},
}The website design was adapted from nerfies.